
本記事は、Googleの検索システムの裏側で動いている「クエリファンアウト」に関する記事です。「用語の意味」「仕組みの概要」「仕組みに対応するための対策」について解説します。
武田淳|SEO・LLMOコンサルタント
上場メーカーにてマーケティング・SEOを担当|2023年に独立|「K塾」としてSEOコンサルティング事業を開始。(K塾のサービス内容はこちら)
- マーケター歴18年/SEO歴9年(2026年4月時点)
- SEO検定1級:SEO検定合格者ページ
- Xにて「LLMOに関するノウハウ」を継続発信中
クエリファンアウトとは|用語の意味・仕組みの概要
まずは「言葉の意味」と「大まかな仕組み」について簡単に解説します。
用語の意味|クエリファンアウトは検索システムの「裏側の仕組み」
クエリファンアウト(Query fan-out)とは、Googleの検索システムがAI Overviews および AIモード の回答を生成する際に、「システムの裏側で走っている仕組み(手法・技術)」を指します。
「クエリ(Query)」とはキーワードのことで、「ファンアウト(fan-out)」とは、「扇状に広げる」という意味です。
関連記事:クエリとキーワードの厳密な違い
「サブクエリ」という言葉も覚えておきましょう。サブクエリとは、クエリファンアウトの過程で生成される「メインクエリに関連する多数のクエリ」を指します。「サブクエリ」はGoogleの正式用語ではありませんが、SEO業界で広く使われており、クエリファンアウトを理解するうえで非常に重要な用語です。
仕組みの概要|クエリの入力~回答生成までのフロー
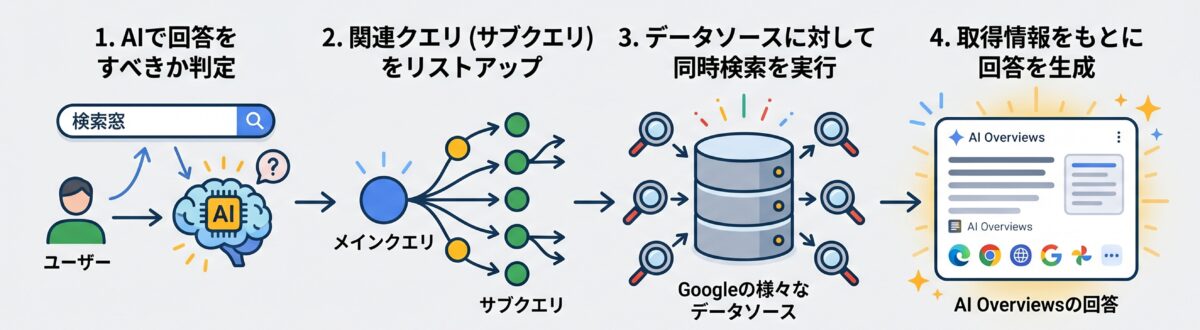
クエリファンアウトの仕組みは、「Googleの検索システムがAI OverviewsやAIモードの回答を生成するまでのフロー」を知ることで理解できるでしょう。以下にフローを示します。
- AIで回答すべきかをシステムが判断する:
ユーザーが検索窓にクエリを入力すると、「AI OverviewsやAIモードの回答を生成するべきか」をシステムが判断します。 - 複数の関連クエリをシステムがリストアップする:
入力されたメインクエリに関連する複数のクエリ(サブクエリ)を、システムがリストアップ(内部で生成)します。 - システムがデータソースに対して検索を実行する:
リストアップした複数のサブクエリを使って、Googleが持つ様々なデータソースに対して、システムが同時に検索をかけます。 - 取得した情報をもとにシステムが回答を生成する:
複数のサブクエリで検索して取得した多くの関連情報をもとに回答が組み立てられ、AI OverviewsやAIモードの回答として生成されます。
この一連のフローを支えているのが、「クエリファンアウトという仕組み(手法・技術)」であり、Googleは以下のように解説しています。
AI による概要(AI Overviews)と AI モードは、「クエリ ファンアウト」手法を使う場合があります。
これは、関連する複数のサブトピックやデータソースに対して検索を実行し、それをもとに回答を組み立てる手法です。
回答を生成する際に、Google の高度なモデルは裏付けとなる関連ウェブページを特定します。
これにより、従来の検索よりも幅広く有益なリンクを表示でき、情報探索に新たな可能性を開きます。
なお、上記の「関連する複数のサブトピックやデータソースに対して検索を実行し」という和訳は分かりにくいかもしれません。英語の原文のニュアンスを正確に紐解くと、「1つの質問を複数のサブトピックに分解し、それらに関する複数の検索を、様々なデータソースにまたがって同時に実行する」という意味になります。
🔰 初心者向け解説
データソースとは、Googleインデックスやナレッジグラフを指します。
Googleインデックスとは、Googleのロボット(クローラー)が世界中のWebサイトを巡回して収集したテキスト、画像、PDF、動画等のデータです。
ナレッジグラフについて詳しく知りたい方は、以下の参考記事をご覧ください。
参考記事:ナレッジグラフとは何か?
クエリファンアウトの内部処理/サブクエリの種類
ここでは、クエリファンアウトの仕組みを深く理解したい方向けに、以下の2点について解説します。
- クエリファンアウトの内部処理のステップ
- クエリファンアウトで生成されるサブクエリの種類
なお、Googleはクエリファンアウトの仕組みの詳細を公開していません。したがって、この解説はあくまでも「SEO業界における通説」という位置づけになります。
クエリファンアウトの内部処理(5ステップあります)
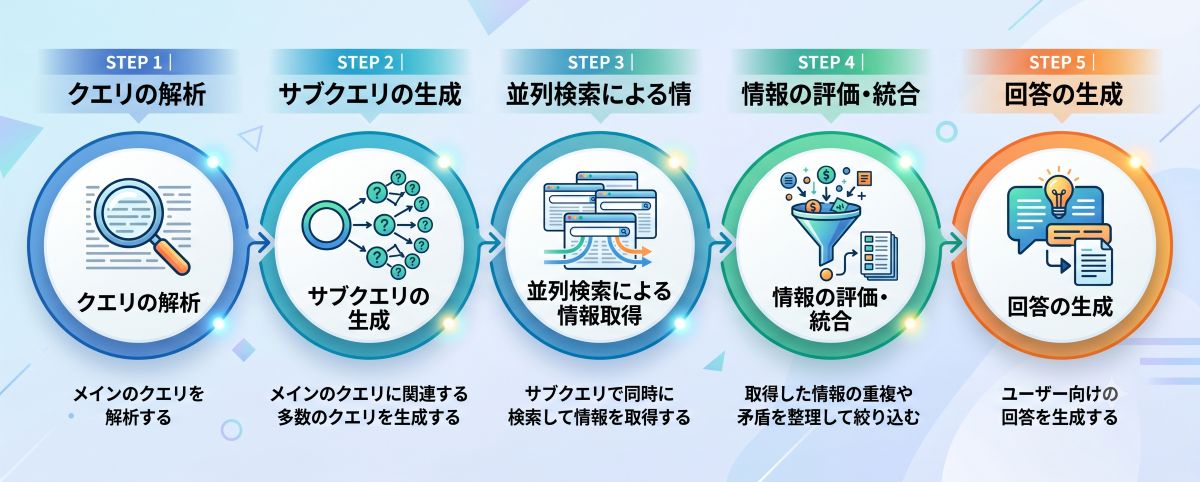
SEO業界では、「クエリファンアウトの内部処理は以下の5ステップで進む」と考えられています。
STEP1|クエリの解析:メインのクエリを解析する
STEP2|サブクエリの生成:メインのクエリに関連する多数のクエリを生成する
STEP3|並列検索による情報取得:サブクエリで同時に検索して情報を取得する
STEP4|情報の評価・統合:取得した情報の重複や矛盾を整理して絞り込む
STEP5|回答の生成:ユーザー向けの回答を生成する
この5ステップは筆者も正しいと考えています。なぜなら、Google検索セントラル(前述)の、「関連する複数のサブトピックやデータソースに対して検索を実行し、それをもとに回答を組み立てる」という文脈に合致しているためです。
サブクエリの種類(8種類あります)
クエリファンアウトで生成されるサブクエリは以下の8種類に分類されると推察されています。
- 曖昧さをクリアにするサブクエリ
- 潜在ニーズを明らかにするサブクエリ
- 詳細を深掘りするサブクエリ
- 与えられた主張を支持または反論する証拠を集めるサブクエリ
- エンティティの取得を行うサブクエリ
- 質問と関連性の高い文書を見つけるサブクエリ
- 直近のセッションの文脈を維持するサブクエリ
- ユーザーに個別化するサブクエリ
この8分類は、クエリファンアウトの技術を支えていると思われる「Googleが申請した特許」をもとに、ヴァリューズ社GM ロベルト氏が推察した分類です。
以下のnote記事で詳しく解説されていますので、クエリファンアウトの仕組みを深く理解したい方は、ぜひご一読ください。
ロベルト氏のnote:
GoogleのAI Modeの核心技術である【クエリファンアウト query fan-out】の裏ではどんな検索が走るのか?
クエリファンアウトに対応するためのLLMO対策
LLMO対策とは、LLM(ChatGPT、Gemini、Google AI Overviews、AIモード等)の回答結果に、自社サイトの情報を引用させたり、ブランド名(社名・商品名・サービス名)を言及させたりするための対策です。
関連記事:LLMO対策の具体的な施策15選|やるべきことは「SEO対策の徹底」
LLMO対策は多岐に渡りますが、ここでは、「クエリファンアウトへの対応に焦点を当てたLLMO対策」を3つ紹介します。
- トピッククラスター戦略を徹底する
- コンテンツの構造をAI向けに最適化する
- 自社ブランドをGoogleにエンティティとして認識させる
LLMO対策① トピッククラスター戦略を徹底する
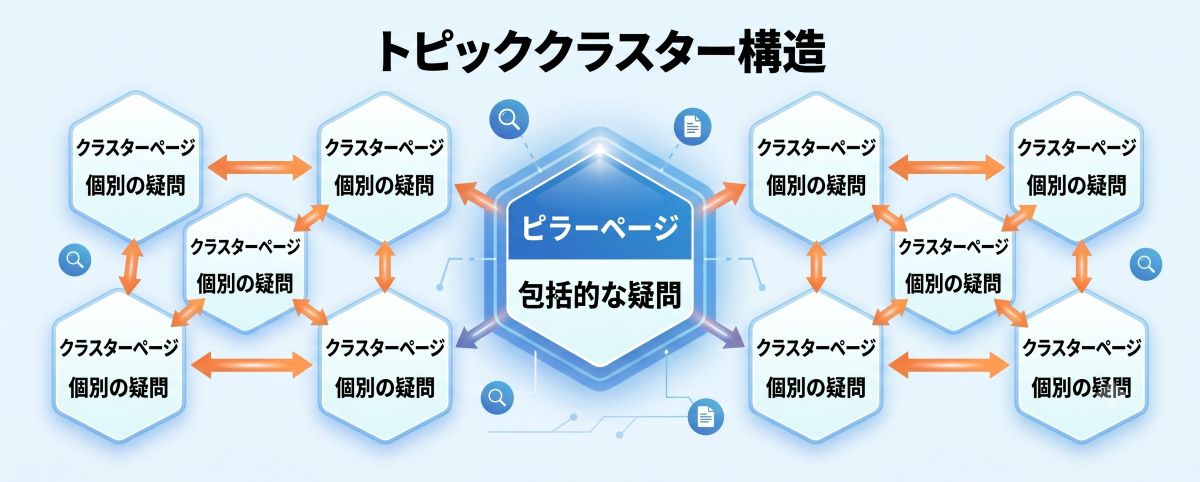
クエリファンアウトに対応するには、「トピッククラスター戦略」の徹底が必須です。
トピッククラスターとは、「ユーザーの包括的な疑問に答えるページ(ピラーページ)」と、「ユーザーの個別の疑問に答えるページ(クラスターページ)」を内部リンクで繋げたサイト構造を指します。
クエリファンアウトのメインクエリに対応するのは、ピラーページ(親記事)です。クラスターページ(子記事・孫記事)は、サブクエリに対応します。
SEO対策において、単一のキーワードのみ対策しておけばよかったのは2000年代までであり、2010年代以降は、サイトの「網羅性」が必須になりました。2017年に登場したトピッククラスター戦略は、既にSEO対策の常識になっていますが、AI検索時代は、これまで以上の徹底が求められます。
LLMO対策② コンテンツの構造をAI向けに最適化する
クエリファンアウトに対応するためには、AIが情報を取得しやすい「型」を取り入れる必要があります。なぜなら、AIはサブクエリに対する回答となる部分をページ内からピンポイントで取得して統合するからです。
AIが迷わず情報を取得できるように、以下の点に留意してコンテンツを制作しましょう。
- 見出しを最適化する:
見出しそのものを、AIが内部で生成しそうな「サブクエリ(疑問文)」に寄せることで、AIの並列検索に合致する確率を高めます。 - セクションの冒頭に結論を書く:
AIはサブクエリに対する「明確な答え」を探しているため、無駄な前置きは省き、冒頭でストレートに結論を提示します。 - トピックごとに情報をコンパクトにまとめる:
AIはテキストデータを300〜700文字程度(日本語の場合)に分割する処理を行っているためです(チャンク・チャンキング)。 - 箇条書き(リスト形式)を多用する:
複数の要素や手順を並べる際は、箇条書き(リスト形式)を用いて記述します。 - よくある質問(FAQ)を入れる:
FAQの「Q」はサブクエリと一致しやすく、素早く情報を取得できるため、AIはFAQを積極的に参照する傾向があります。
LLMO対策③ 自社ブランドをGoogleにエンティティとして認識させる
クエリファンアウトに対応するためには、自社のブランドやサービスをGoogleに「エンティティ(一意の実体)」として認識させ、その評価(エンティティ・スコア)を高めていく必要があります。
これは、GoogleのAIがサブクエリを自動生成する際、エンティティ情報が格納されている「ナレッジグラフ」を参照しているためです。また、前述のロベルト氏のサブクエリの8分類にも、「エンティティの取得を行うサブクエリ」が挙げられています。
では、Googleにエンティティとして認められるためには、何をすればよいのでしょうか?Googleは「具体的な手法」を明かしていませんが、SEO業界では以下の施策が有効と考えられています。
- 構造化データのマークアップ:
企業の場合「Organization(組織)」、個人の場合「Person(個人)」の構造化データをマークアップします。 - NAP情報の統一:
自社サイト、SNSアカウント、Googleビジネスプロフィール上の、社名・住所・電話番号(NAP情報)の表記ゆれを解消します。 - 権威性の高い被リンクの獲得:
既にエンティティとして認識されている公的機関、学術機関、大手企業からの被リンク獲得を目指します。 - Web上でのサイテーションの獲得:
他社サイト、YouTube、SNS、ニュースなどでの、ブランド名(社名、商品名、サービス名等)の言及を増やします。
これらの施策は、従来からあるSEOの「外部対策(オフページSEO)」ですが、クエリファンアウトに対応するためにも、今後はますます重要になります。なお、Googleからエンティティとして認識・評価されるには、E-E-A-T(経験・専門性・権威性・信頼性)が備わっていることが必須であることは言うまでもありません。
🔰 初心者向け解説
エンティティ(entity)とは、「実体」「存在」等の意味を持つ英単語で、他とは明確に区別された一意の対象物を指します。
エンティティの代表例は、特定の人物・組織・製品・地域・出来事・概念等ですが、AIはエンティティを単なる固有名詞ではなく「他のエンティティと関連付けて(紐づけて)」理解します。
たとえば「大谷翔平(人物)」というエンティティの場合、AI は「ドジャース(組織名)」「野球選手(職業)」「二刀流(概念)」といった他のエンティティと紐づけて認識しているのです。
ChatGPT等にもクエリファンアウトと同様の技術が使われている
本記事では、GoogleのAI(AI Overviews・AIモード)の裏側で動いているクエリファンアウトについて解説してきました。クエリファンアウトはGoogleが付けた名前ですが、その技術はGoogleが独自に開発したわけではありません。
メインクエリから複数のサブクエリを生成・検索し、取得した情報を統合して回答を作るアプローチは、「RAG(検索拡張生成)」と呼ばれる技術から発展したものです。
下表のとおり、ChatGPT(OpenAI)やPerplexity、Claude等、すべての主要なAIアシスタントで、クエリファンアウトとほぼ同じ仕組みが広く使われています。
| AIアシスタント | 技術・仕組み |
|---|---|
| ChatGPT | プロンプトから必要な情報を判断し、内部で複数の検索クエリを自動生成・実行して包括的な回答を生成する |
| Perplexity | 「Pro Search」機能等において、複雑な質問を多段階に分けて推論・検索している |
| Copilot | AI検索機能(Generative Search)の裏側で、関連する複数の検索クエリを内部で発行して情報を集約している |
| Claude | 連携するWeb検索ツールを活用し、質問に答えるために必要な関連クエリを動的に発行して情報を取得している |
このように、Googleのクエリファンアウトと同様の仕組みは、メジャーなAIアシスタントに共通して備わっています。したがって、前述のの「トピッククラスター」「コンテンツの構造」「エンティティ」に関する施策は、Google以外のAIアシスタントに対しても有効です。
まとめ|全てのAIに共通するクエリファンアウトを前提にLLMO対策を推進
クエリファンアウトとは、GoogleがAIによる回答を生成する際、1つの検索キーワードから関連する複数の「サブクエリ」を自動生成し、様々な情報源を同時に並列検索して統合する裏側の仕組みです 。
クエリファンアウトに対応するためのLLMO対策として、主に以下の3点が不可欠になります 。
- トピッククラスター戦略の徹底:親記事と子記事を内部リンクで繋ぎ、ユーザーの疑問を網羅的に解決するサイト構造を作る
- コンテンツ構造の最適化:冒頭での結論提示や箇条書きの多用など、AIが情報をピンポイントで取得しやすい「型」を取り入れる
- エンティティの確立:構造化マークアップやサイテーションの獲得により、自社ブランドをエンティティとしてGoogleに認識させる
Google以外の生成AIにも、クエリファンアウトと同様の仕組みは組み込まれているため、これらの施策もあらゆる生成AIに対して有効と考えられます。
SEO・LLMOに関するご相談は、以下よりお気軽にご連絡ください。
FAQ(よくある質問)
- QクエリファンアウトではGeminiが動いているのですか?
- A
「クエリファンアウトという仕組みの一部をGeminiが補完している」と表現するのが適切です。具体的には、サブクエリの生成やAI Overviews・AIモードの回答文の生成(文章としての統合・要約)をGeminiが担っています。
- Qクエリファンアウトで生成されるサブクエリの数はどのぐらいですか?
- A
以下の引用のとおり、通常の検索では数個~10数個、ディープリサーチ(ディープサーチ)では数百個のサブクエリが生成されていると考えられています。当然、クエリによって、生成されるサブクエリの数は変わります。
赤いスマートフォンケースをオンラインで購入したいとき、適切な商品を見つけるまでに何回検索しますか?AI モードでは通常 5〜11 回です。ChatGPT Deep Research では 420 回でした。
引用元:「クエリファンアウトとは?AI 検索の隠れたクエリ技術を解説」(April 16, 2026年4月16日付 Ahrefs blog)
より詳細な回答が必要な質問には、AIモードにディープサーチ機能を追加し、高度な調査機能を提供します。ディープサーチは、従来のクエリファンアウト技術をさらに進化させたものです。数百件の検索を実行し、様々な情報を総合的に分析して、専門家レベルの参考文献付きレポートをわずか数分で作成できるため、何時間もの調査時間を節約できます。
引用元:「検索におけるAI:情報からインテリジェンスへ」(2025年5月20日付 Google blog)
- Qクエリファンアウトで「どんなサブクエリが生成されているか」を確認できますか?
- A
確認できません。Googleはクエリファンアウトの仕組みの詳細を公開しておらず、内部で生成されたサブクエリを直接確認できる公式ツールも存在しません。
- Q「リンクだけ貼るか」「言及だけするか」もクエリファンアウトで処理されているのですか?
- A
はい、クエリファンアウトの最終段階である「情報の情報の評価・統合」および「回答の生成」のプロセスで処理されています。もちろん、クエリファンアウトの過程でページの情報が参照(取得)されたからといって、必ずしも引用リンクが貼られたり(引用されたり)、ブランド名が表示される(言及される)とは限りません。
- QChatGPTもエンティティを参照していますか?
- A
不明です。「ChatGPTはGoogleのナレッジグラフに相当するエンティティデータベースを参照している」といったOpenAIの公式声明はWeb上に見当たりません。OpenAIは「内部で複数の検索クエリを自動生成・実行している」としか述べていません。
- Qクエリファンアウトはいつ頃から言われ始めましたか?
- A
SEO業界で話題になり始めたのは2025年5月です。Googleが公式ドキュメントでAIモードの仕組みとして明言したことがきっかけでした。しかし、2014年の公開特許にはすでに類似の概念が記述されています。